diff --git a/README.md b/README.md
new file mode 100644
index 0000000..67cfbeb
--- /dev/null
+++ b/README.md
@@ -0,0 +1,132 @@
+# Ultimate Vocal Remover GUI v5.1.0
+ +
+[](https://github.com/anjok07/ultimatevocalremovergui/releases/latest)
+[](https://github.com/anjok07/ultimatevocalremovergui/releases)
+
+## About
+
+This application uses state of the art AI and models to remove vocals from tracks. All of the models provided in this package were trained by UVR's core developers.
+
+- **Core Developers**
+ - [Anjok07](https://github.com/anjok07)- Model collaborator & UVR developer.
+ - [aufr33](https://github.com/aufr33) - Model collaborator & fellow UVR developer. This project wouldn't be what it is without your help. Thank you for your continued support!
+ - [DilanBoskan](https://github.com/DilanBoskan) - Your contributions at the start of this project were essential to the success of UVR. Thank you!
+
+
+## Change Log
+
+- **v4 vs. v5**
+ - The v5 models significantly outperform the v4 models.
+ - The extraction's aggressiveness can be adjusted using the "Aggression Setting". The default value of 10 is optimal for most tracks.
+ - All v2 and v4 models have been removed.
+ - Ensemble Mode added - This allows the user to get the strongest result from each model.
+ - Stacked models have been entirely removed.
+ - Stacked model feature has been replaced by the new aggression setting and model ensembling.
+ - The NFFT, HOP_SIZE, and SR values are now set internally.
+ - MDX-NET AI engine and model support
+
+## Installation
+
+UVR v5.2.0 and all of it's features are only available on Windows at this time. However, this application can be run on Mac & Linux by performing a manual install, though some features may not be available on those platforms.
+
+### Windows Installation
+
+The installer does not require any prerequisite installations. All of the required libraries are included in the installation.
+
+1. Download the UVR installer [here]()
+2.
+
+### Manual Developer Installation
+
+1. Download & install Python 3.9.8 [here](https://www.python.org/ftp/python/3.9.8/python-3.9.8-amd64.exe) (Windows link)
+ - **Note:** Ensure the *"Add Python 3.9 to PATH"* box is checked
+2. Download the Source code zip here - https://github.com/Anjok07/ultimatevocalremovergui/archive/refs/heads/master.zip
+3. Download the models.zip here - https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.1.0/models.zip
+4. Extract the *ultimatevocalremovergui-master* folder within ultimatevocalremovergui-master.zip where ever you wish.
+5. Extract the *models* folder within models.zip to the *ultimatevocalremovergui-master* directory.
+ - **Note:** At this time, the GUI is hardcoded to run the models included in this package only.
+6. Open the command prompt from the ultimatevocalremovergui-master directory and run the following commands, separately -
+
+```
+pip install --no-cache-dir -r requirements.txt
+```
+```
+pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
+```
+
+- FFmpeg
+
+ - FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg can be found on YouTube, WikiHow, Reddit, GitHub, and many other sources around the web.
+
+ - **Note:** If you are experiencing any errors when attempting to process any media files, not in the *.wav* format, please ensure FFmpeg is installed & configured correctly.
+
+- Running the GUI & Models
+
+ - Open the file labeled *'VocalRemover.py'*.
+ - It's recommended that you create a shortcut for the file labeled *'VocalRemover.py'* to your desktop for easy access.
+ - **Note:** If you are unable to open the *'VocalRemover.py'* file, please go to the [**troubleshooting**](https://github.com/Anjok07/ultimatevocalremovergui/tree/beta#troubleshooting) section below.
+ - **Note:** All output audio files will be in the *'.wav'* format.
+
+## Application Manual
+
+**General Options**
+
+
+
+[](https://github.com/anjok07/ultimatevocalremovergui/releases/latest)
+[](https://github.com/anjok07/ultimatevocalremovergui/releases)
+
+## About
+
+This application uses state of the art AI and models to remove vocals from tracks. All of the models provided in this package were trained by UVR's core developers.
+
+- **Core Developers**
+ - [Anjok07](https://github.com/anjok07)- Model collaborator & UVR developer.
+ - [aufr33](https://github.com/aufr33) - Model collaborator & fellow UVR developer. This project wouldn't be what it is without your help. Thank you for your continued support!
+ - [DilanBoskan](https://github.com/DilanBoskan) - Your contributions at the start of this project were essential to the success of UVR. Thank you!
+
+
+## Change Log
+
+- **v4 vs. v5**
+ - The v5 models significantly outperform the v4 models.
+ - The extraction's aggressiveness can be adjusted using the "Aggression Setting". The default value of 10 is optimal for most tracks.
+ - All v2 and v4 models have been removed.
+ - Ensemble Mode added - This allows the user to get the strongest result from each model.
+ - Stacked models have been entirely removed.
+ - Stacked model feature has been replaced by the new aggression setting and model ensembling.
+ - The NFFT, HOP_SIZE, and SR values are now set internally.
+ - MDX-NET AI engine and model support
+
+## Installation
+
+UVR v5.2.0 and all of it's features are only available on Windows at this time. However, this application can be run on Mac & Linux by performing a manual install, though some features may not be available on those platforms.
+
+### Windows Installation
+
+The installer does not require any prerequisite installations. All of the required libraries are included in the installation.
+
+1. Download the UVR installer [here]()
+2.
+
+### Manual Developer Installation
+
+1. Download & install Python 3.9.8 [here](https://www.python.org/ftp/python/3.9.8/python-3.9.8-amd64.exe) (Windows link)
+ - **Note:** Ensure the *"Add Python 3.9 to PATH"* box is checked
+2. Download the Source code zip here - https://github.com/Anjok07/ultimatevocalremovergui/archive/refs/heads/master.zip
+3. Download the models.zip here - https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.1.0/models.zip
+4. Extract the *ultimatevocalremovergui-master* folder within ultimatevocalremovergui-master.zip where ever you wish.
+5. Extract the *models* folder within models.zip to the *ultimatevocalremovergui-master* directory.
+ - **Note:** At this time, the GUI is hardcoded to run the models included in this package only.
+6. Open the command prompt from the ultimatevocalremovergui-master directory and run the following commands, separately -
+
+```
+pip install --no-cache-dir -r requirements.txt
+```
+```
+pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
+```
+
+- FFmpeg
+
+ - FFmpeg must be installed and configured for the application to process any track that isn't a *.wav* file. Instructions for installing FFmpeg can be found on YouTube, WikiHow, Reddit, GitHub, and many other sources around the web.
+
+ - **Note:** If you are experiencing any errors when attempting to process any media files, not in the *.wav* format, please ensure FFmpeg is installed & configured correctly.
+
+- Running the GUI & Models
+
+ - Open the file labeled *'VocalRemover.py'*.
+ - It's recommended that you create a shortcut for the file labeled *'VocalRemover.py'* to your desktop for easy access.
+ - **Note:** If you are unable to open the *'VocalRemover.py'* file, please go to the [**troubleshooting**](https://github.com/Anjok07/ultimatevocalremovergui/tree/beta#troubleshooting) section below.
+ - **Note:** All output audio files will be in the *'.wav'* format.
+
+## Application Manual
+
+**General Options**
+
+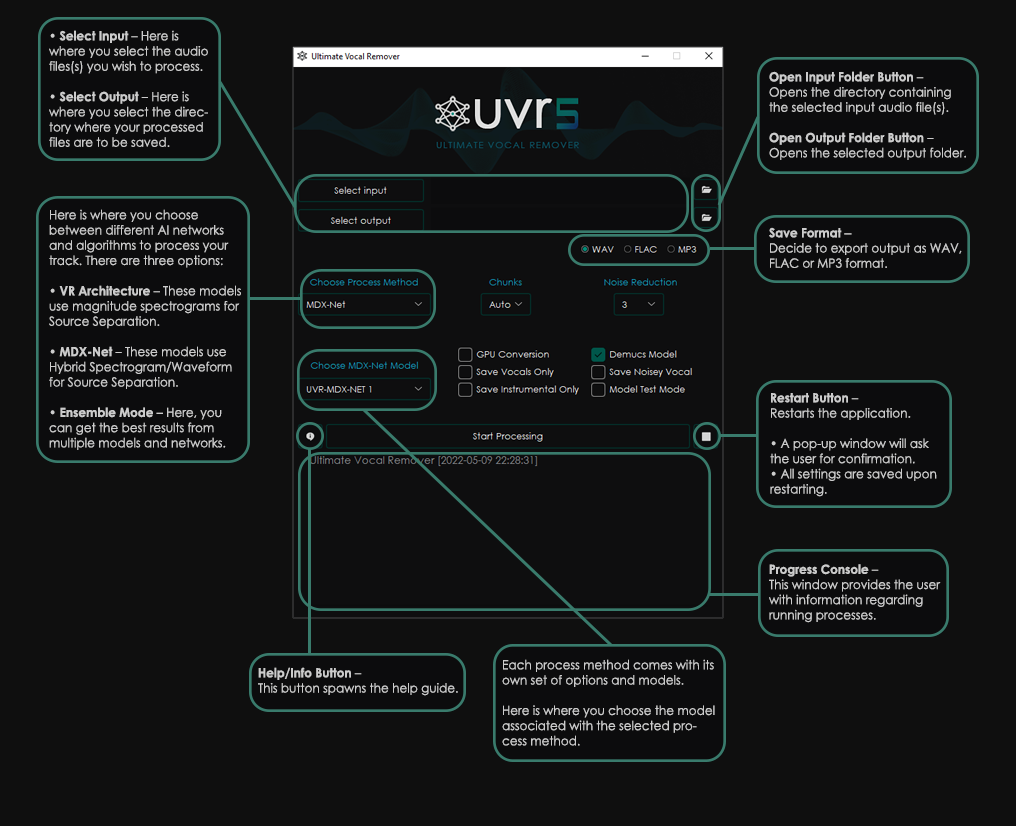 +
+**VR Architecture Options**
+
+
+
+**VR Architecture Options**
+
+ +
+**MDX-Net Options**
+
+
+
+**MDX-Net Options**
+
+ +
+**Ensemble Options**
+
+
+
+**Ensemble Options**
+
+ +
+**User Ensemble**
+
+
+
+**User Ensemble**
+
+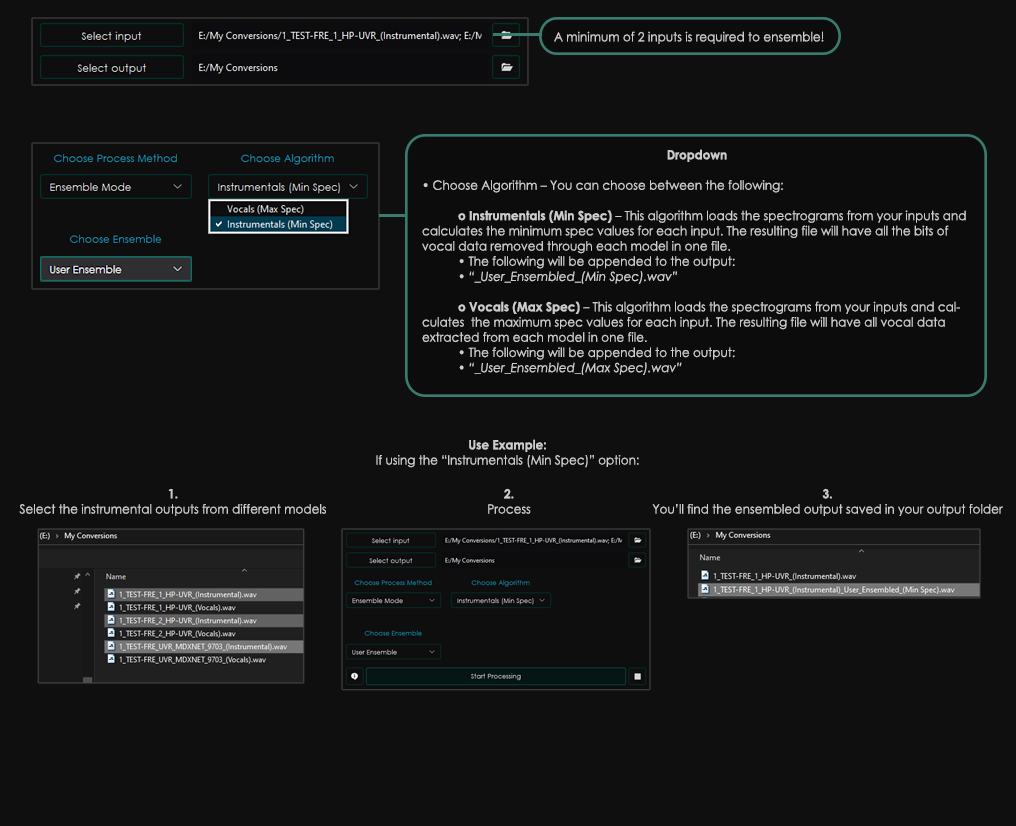 +
+## Other GUI Notes
+
+- The application will automatically remember your *'save to'* path upon closing and reopening until it's changed.
+ - **Note:** The last directory accessed within the application will also be remembered.
+- Multiple conversions are supported.
+- The ability to drag & drop audio files to convert has also been added.
+- Conversion times will significantly depend on your hardware.
+ - **Note:** This application will *not* be friendly to older or budget hardware. Please proceed with caution! Please pay attention to your PC and make sure it doesn't overheat. ***We are not responsible for any hardware damage.***
+
+## Troubleshooting
+
+### Common Issues
+
+- This application is only compatible with 64-bit platforms.
+- This application is not compatible with 32-bit versions of Python. Please make sure your version of Python is 64-bit.
+- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
+
+### Issue Reporting
+
+Please be as detailed as possible when posting a new issue. Navigate to the "Error Log" tab in the Help Guide for detailed error information that can be provided to us.
+
+## License
+
+The **Ultimate Vocal Remover GUI** code is [MIT-licensed](LICENSE).
+
+- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers Anjok07, aufr33, & tsurumeso.
+
+## Additional Credits
+
+- [tsurumeso](https://github.com/tsurumeso) - Developed the original VR Architecture code.
+- [Kuielab & Woosung Choi](https://github.com/kuielab) - Developed the original MDX-Net AI code.
+- [Adefossez & Demucs](https://github.com/facebookresearch/demucs) - Developed the original MDX-Net AI code.
+
+## Contributing
+
+- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and/or modify as they wish.
+- Please note that we do not maintain or directly support any of tsurumesos AI application code. We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
+
+## References
+- [1] Takahashi et al., "Multi-scale Multi-band DenseNets for Audio Source Separation", https://arxiv.org/pdf/1706.09588.pdf
+
+## Other GUI Notes
+
+- The application will automatically remember your *'save to'* path upon closing and reopening until it's changed.
+ - **Note:** The last directory accessed within the application will also be remembered.
+- Multiple conversions are supported.
+- The ability to drag & drop audio files to convert has also been added.
+- Conversion times will significantly depend on your hardware.
+ - **Note:** This application will *not* be friendly to older or budget hardware. Please proceed with caution! Please pay attention to your PC and make sure it doesn't overheat. ***We are not responsible for any hardware damage.***
+
+## Troubleshooting
+
+### Common Issues
+
+- This application is only compatible with 64-bit platforms.
+- This application is not compatible with 32-bit versions of Python. Please make sure your version of Python is 64-bit.
+- If FFmpeg is not installed, the application will throw an error if the user attempts to convert a non-WAV file.
+
+### Issue Reporting
+
+Please be as detailed as possible when posting a new issue. Navigate to the "Error Log" tab in the Help Guide for detailed error information that can be provided to us.
+
+## License
+
+The **Ultimate Vocal Remover GUI** code is [MIT-licensed](LICENSE).
+
+- **Please Note:** For all third-party application developers who wish to use our models, please honor the MIT license by providing credit to UVR and its developers Anjok07, aufr33, & tsurumeso.
+
+## Additional Credits
+
+- [tsurumeso](https://github.com/tsurumeso) - Developed the original VR Architecture code.
+- [Kuielab & Woosung Choi](https://github.com/kuielab) - Developed the original MDX-Net AI code.
+- [Adefossez & Demucs](https://github.com/facebookresearch/demucs) - Developed the original MDX-Net AI code.
+
+## Contributing
+
+- For anyone interested in the ongoing development of **Ultimate Vocal Remover GUI**, please send us a pull request, and we will review it. This project is 100% open-source and free for anyone to use and/or modify as they wish.
+- Please note that we do not maintain or directly support any of tsurumesos AI application code. We only maintain the development and support for the **Ultimate Vocal Remover GUI** and the models provided.
+
+## References
+- [1] Takahashi et al., "Multi-scale Multi-band DenseNets for Audio Source Separation", https://arxiv.org/pdf/1706.09588.pdf